What is bio-statistics and how does it relate to me ? I am often asked this question, and now I think I may have an answer. With the advent of the Internet, we are now in the Age of Information, and when it comes to "statistical data analysis", a rather imposing mouthful, to quote a recent article in the New York Times (and I paraphrase):
In field after field, computing and the Web are creating new realms of data to explore - sensor signals, surveillance tapes, social network chatter, public records and more. We're rapidly entering a world where everything can be monitored and measured, but the big problem is going to be the ability of humans to use, analyze and make sense of the data. Strong correlations of data do not necessarily prove a cause-and-effect link. For example, in the late 1940s, before there was a polio vaccine, public health experts in America noted that polio cases increased in step with the consumption of ice cream and soft drinks. Eliminating such treats was even recommended as part of an anti-polio diet. It turned out that polio outbreaks were most common in the hot months of summer, when people naturally ate more ice cream, showing only an association. Computers do what they are good at, which is trawling these massive data sets for something that is mathematically odd, and humans do what they are good at and explain these anomalies.
To analyze statistical data, we use computer programs as tools to work with such information as
biological data. Yet another recent article in the New York Times compares and contrasts two of these computer programs,
R and
SAS (and again I paraphrase):
SAS Institute (the privately held business software company that specializes in data analysis)'s namesake SAS has been the preferred tool of scholars and corporate managers. But the R Project has also quickly found a following because statisticians, engineers and scientists without computer programming skills find it easy to use.
Reference:
http://www.nytimes.com/2009/08/06/technology/06stats.htmlhttp://www.nytimes.com/2009/01/07/technology/business-computing/07program.html?pagewanted=allSo "Statistical Data Analysis" in the abstract sense is a formidable journey of a thousand miles, but the bite-size journey's first step involves importing a set of data into the tool (I'm assuming you already obtained, installed, and are running the software). For purposes of demonstration, I've created a data set using the actual previous year's receipts I had gathered and saved from each and every time I filled my car's tank with gasoline:
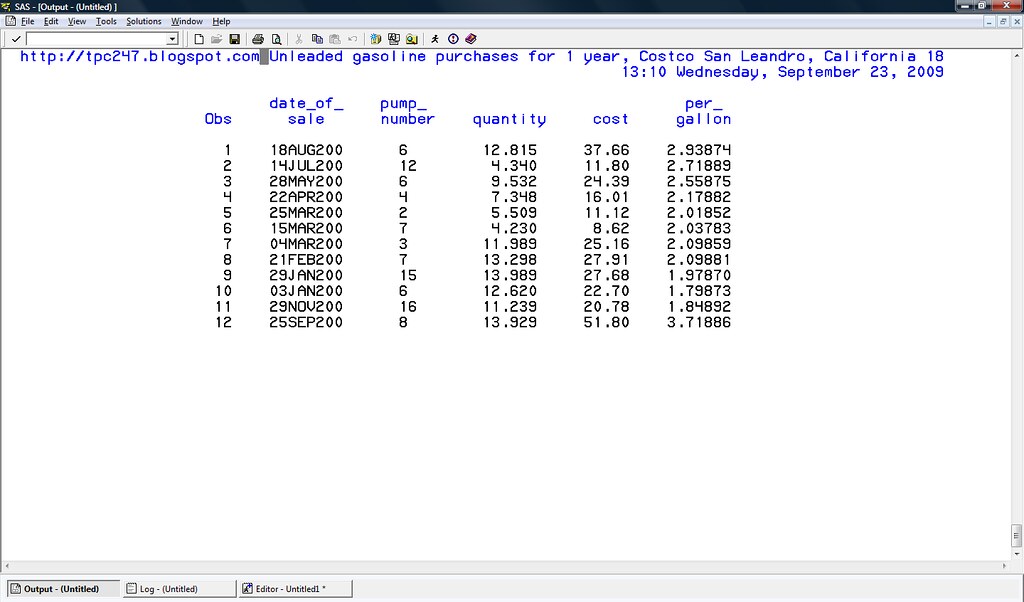
18AUG2009 6 12.815 37.66
14JUL2009 12 4.340 11.8
28MAY2009 6 9.532 24.39
22APR2009 4 7.348 16.01
25MAR2009 2 5.509 11.12
15MAR2009 7 4.230 8.62
04MAR2009 3 11.989 25.16
21FEB2009 7 13.298 27.91
29JAN2009 15 13.989 27.68
03JAN2009 6 12.620 22.70
29NOV2008 16 11.239 20.78
25SEP2008 8 13.929 51.80
Note that on the tail end of the second line, in the last figure, 11.8, I omitted a zero ('0') when I was typing the data in. We'll come back to that later. I decided to record the following four fields for each time I filled the gas tank (all took place at Costco in San Leandro):
- date of purchase
- pump number
- quantity of gas obtained, in gallons
- cost of the transaction
In both tools, R and SAS, we will then divide cost by quantity and generate a fifth field, price per gallon.
To import a dataset into your software, you can either read from a file, or copy and paste it in (although for R, you will copy the data set, but you won't actually paste anything). The following scripts have been tested on R versions 2.8.1, 2.9.2 and SAS version 9.1.3 Service Pack 4.
- To read data from a file within R and SAS:
- identify the path to the file containing your data set. Let's say the path is:
G:\tpc247\petrol.txt
if you're on Windows, the convention is to delimit or separate folders with a backslash, but this poses a problem for software that is trained to recognize tabs and carriage returns and newlines as '\t', '\r' and '\n' respectively. For reasons of cross-platform compatibility, if there are backslashes in your Windows path, add another one right next to it:
G:\\tpc247\\petrol.txt
or replace the backslash with a forward slash:
G:/tpc247/petrol.txt
- at the command prompt, input and run the following incantations:
- R:
petrol_01 = read.table("G:/tpc247/petrol.txt", header=FALSE, col.names=c('date', 'pump', 'quantity', 'cost'))
petrol_01$per_gallon <- petrol_01$cost / petrol_01$quantity
petrol_01 - SAS:
data petrol_01;
infile "G:/tpc247/petrol.txt";
input date_of_sale$ 5-13 pump_number$ 16-17 quantity 20-25 cost 28-32;
per_gallon = cost / quantity;
proc print data=petrol_01;
title 'Unleaded gasoline purchase history for 1 year, San Leandro, California Costco';
run;
- To read data from computer memory in R and SAS:
- R:
- copy and paste this into R, but don't actually run the incantation yet:
petrol_01 = read.table("clipboard", col.names=c('date', 'pump', 'quantity', 'cost')) - copy your data set, then run the previous incantation
- run the rest as you normally would:
petrol_01$price_per_gallon <- petrol_01$cost / petrol_01$quantity
petrol_01
- SAS:
data petrol_01;
input date_of_sale$ 5-13 pump_number$ 15-16 quantity 18-23 cost 25-29;
per_gallon = cost / quantity;
datalines;
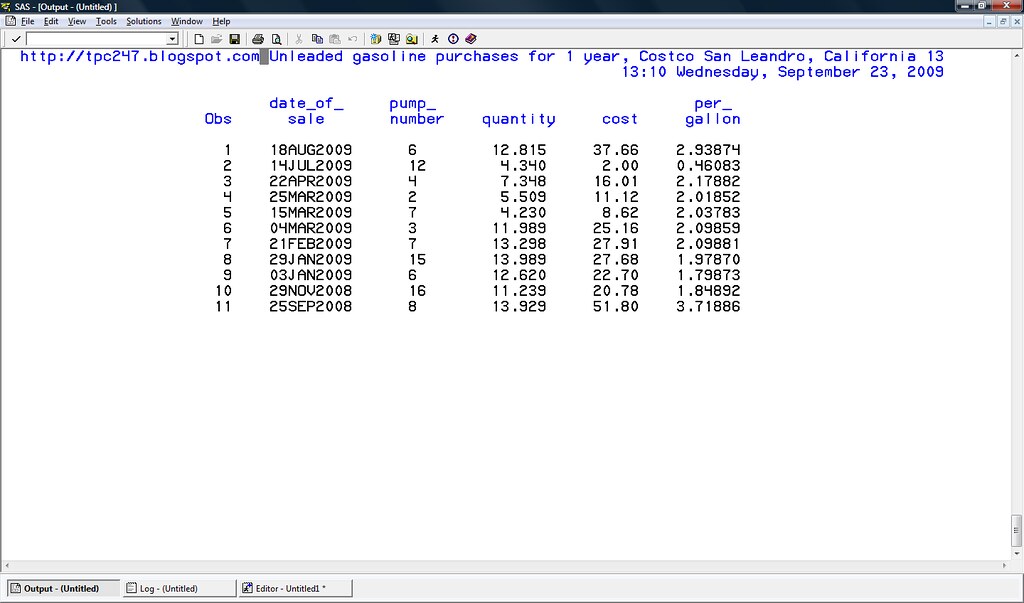
18AUG2009 6 12.815 37.66
14JUL2009 12 4.340 11.8
28MAY2009 6 9.532 24.39
22APR2009 4 7.348 16.01
25MAR2009 2 5.509 11.12
15MAR2009 7 4.230 8.62
04MAR2009 3 11.989 25.16
21FEB2009 7 13.298 27.91
29JAN2009 15 13.989 27.68
03JAN2009 6 12.620 22.70
29NOV2008 16 11.239 20.78
25SEP2008 8 13.929 51.80
proc print data=petrol_01;
title 'Unleaded gasoline purchase history for 1 year, Costco in San Leandro, California';
run;
Coming back to the omitted zero ('0') on the second line in our last figure, 11.8, you might find it amusing how finicky R and SAS are about what they eat. Putting this tutorial together gave me the opportunity to learn some valuable things about the two tools. Just like a toddler can be very picky about the food she feels like taking in her, feeding data to R and SAS and ensuring they digest the data correctly may require some forethought and planning. When importing the dataset into both tools from a file, I noticed that in:
Other separators and delimiters
If you have commas separating your data:
18AUG2009, 6, 12.815, 37.66
14JUL2009, 12, 4.340, 11.8
28MAY2009, 6, 9.532, 24.39
22APR2009, 4, 7.348, 16.01
25MAR2009, 2, 5.509, 11.12
15MAR2009, 7, 4.230, 8.62
04MAR2009, 3, 11.989, 25.16
21FEB2009, 7, 13.298, 27.91
29JAN2009, 15, 13.989, 27.68
03JAN2009, 6, 12.620, 22.70
29NOV2008, 16, 11.239, 20.78
25SEP2008, 8, 13.929, 51.80
In:
When importing data into R or SAS, you need to look at your dataset, and tell R or SAS exactly what to expect, or your statistical data analysis software may complain.
Reference:
http://www.stat.psu.edu/online/program/stat481/01importingI/02importingI_styles.html
















{kind=link}